
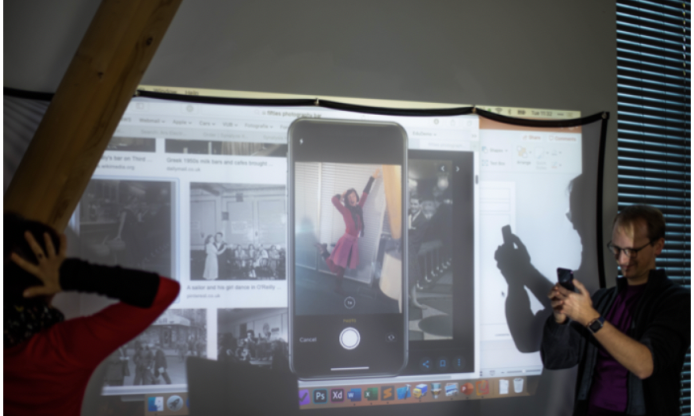
img. Live interactive demo of the visual similarity app, taking a picture of a person dancing, Frederik Temmermans (right), Erica Charalambous (left), Photo courtesy Maria Polodeanu.
In this blog, we tell the story of an interesting task of the Fifties in Europe Kaleidoscope project: the visual similarity search tool. Basing on the visual imagery of the 1950s, this task wanted to demonstrate the capabilities as well as current restrictions of deep learning techniques in the training process for an algorithm which would recognize the content of an image and generate appropriate metadata from automated extraction. This technology is enough mature to grant good results and to allow the development of demo applications which will be the basis for enhanced user engagement features in online repositories like Europeana.
The work done in the project and a test app to showcase potential uses of the technology was presented in various occasions to get user feedback to steer further developments fitted to the needs of stakeholders in the cultural heritage community. The activity was led by Frederik Temmermans (IMEC) with participation of all project partners. Frederik describes the technology underlying the tool: The recognition algorithm is trained using deep learning techniques. However, typically deep learning techniques can only be successfully applied if they are fed with a sufficiently large training data set containing millions of sample assets. However, for the categories which were defined in the Kaleidoscope project, only a few hundred samples per category were available for training. Therefore, the samples are trained on top of a model which is already trained for particular image recognition tasks. Hence, good results could be achieved with a relatively small training set.
For the Kaleidoscope demo application, a selection of image categories were defined including: fashion: dresses with patterns, dancing and protest/demonstration to name a few. The algorithm is limited to the recognition of images that fit in one or more of the predefined categories. In addition, some of the categories can have various interpretations. For example, a supermarket interior and a supermarket exterior both fit in the Supermarket category, however, their visual content is very different.
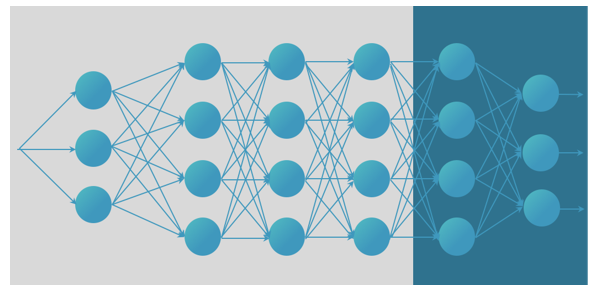
We built a specific model (turquoise) on top of an existing model trained in particular for image recognition (gray).
Visual similarity specifications
It was already mentioned that the overall scope is to train an algorithm that can identify similarity between images based on visual properties. In order to train the algorithm, a set of suitable categories was needed as well as a sufficiently large training data set. To define the categories all project members had to work together to find categories which fulfill the following requirements:
- The categories should fit within the general narrative of the fifties.
- Selected categories are suitable for storytelling.
- Each category should imply a specific visual similarity in the images.
- A category is only suitable if a sufficiently large set of training images can be collected.
In order to define a list of categories that comply with these requirements the following actions were taken:
- Several online meetings were organised to discuss ideas and explain the technical requirements based on illustrative examples.
- Pinterest boards were created with sets of images with initial categories defined during the online meetings.
- A workshop was organized where members with different backgrounds joined together to collect categories during a brainstorm session. The final selection of categories was made during this event.
The workshop was organized in Brussels on 10 and 11 December 2018. The aim was to define a set of approximately 20 concepts which comply with the aforementioned specifications (cfr. MS3). To that end, participants of the workshop were divided according to their various backgrounds. In particular they were categorised as (1) technical expert, (2) curator, (3) content provider or (4) other. Based on these backgrounds, four mixed teams were composed to work together during the brainstorming session. During four subsequent sessions, each team had to work on four themes:
- Scenes: photos that are similar because they portray a specific scene, e.g. family in a living room watching TV or a group of people in a bar drinking coffee.
- Equipment / techniques: selection of photos that show similarity because of specific photographic equipment or techniques that were used.
- Style: photos that show similarity based on style, for example fashion or architecture.
- Other: imagery with other visual relations such as political or advertorial posters.
After defining the categories, the next step was to gather a sufficiently large dataset. These images were only to be used for training the algorithm and could be sourced via different channels. In practice some tests were conducted with images gathered via Pinterest, but the main training set of images was provided by the project content providers. Content providers were asked to upload photos from their libraries in folders corresponding to the categories.

Some example images for dance, fashion (patterns), jukebox, and protest respectively
In total we gathered ca. 3500 photos for a total of 26 categories, although some categories were better populated than others. Some photos were cropped to focus on specific aspects. For example, suitcases were extracted from the image to let the algorithm focus on these particular objects.

The gathered dataset was used as a training set to train the deep learning frameworks to learn the associated categories. Typically, millions of training samples are needed to successfully apply deep learning. However, our training dataset was limited to only 3500 images with sometimes less than 100 images per category. Therefore, we built upon networks that have already been trained in particular for image recognition tasks. On top of this, we train the model for our specific task. The result is a model that can take new images as an input and assign category labels and a probability. These labels can be used to indicate visual correlation between images, and this allows better search mechanisms.
Mobile app demonstrator
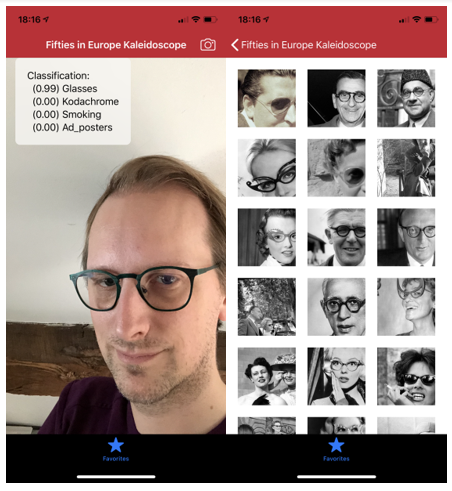
To demonstrate the recognition algorithm we built a mobile demonstrator application. The application iPhone (iOS) allows users to submit a query picture and retrieve images from the fifties which are visually similar. The returned images are selected from the dataset that was gathered from the project partners. Since the application uses the model that we described before, it is currently limited to the trained categories. Instead of selecting a previously stored image, the user can also take a new picture and submit it as an input. This allows for example to take a picture of a dancing person or someone wearing glasses or smoking to find images of the fifties that correspond with these respective categories.
The demonstrator application used to retrieve images of the fifties of people with glasses based on a selfie of a person wearing glasses.
Integration with Europeana
After training the algorithm for visual recognition as described in the previous section, the resulting model can be applied on new images and assign labels corresponding with the defined categories. If this process is applied on a large set of images connections between images can be made based on overlapping labels. As a result, the labels can be used to navigate through images based on their visual content. To insert these labels to our collections, the following process is used:
- A generic query was used to extract image files from Europeana via the WITH platform;
- Labels were assigned to the images using the trained model as described in Task 3.2 and stored in a CSV text file;
- The labels were imported via WITH and assigned to the corresponding images;
- The labels are hidden to the end users but can be used to suggest potentially related images to the user.
The WITH platform uses the Europeana Records and Search API for retrieving collections in order for them to be enriched. Afterwards, the results of the crowdsourced enrichment are exported to the Europeana Annotations Server, via the Europeana Annotation API, in order to publish back the enriched metadata in the Europeana Collection website. Also, the augmented metadata that have been produced so far by crowdsourcing are all available online at the Kaleidoscope portal. Both professionals and amateur users were encouraged to use the WithCrowd platform in order to add and validate specific annotations about 50s photos.
All the Kaleidoscope content hosted on the portal (https://fifties.withculture.eu) is also available for crowdsourcing via the WithCrowd site (https://withcrowd.eu/fifties) where the user can browse the collections, select the most interesting photos and add relative terms from the wikidata or photography thesaurus (see screenshot below). All the inserted annotations are stored in the database and are available at the Kaleidoscope portal (with the relative link) as depicted below.
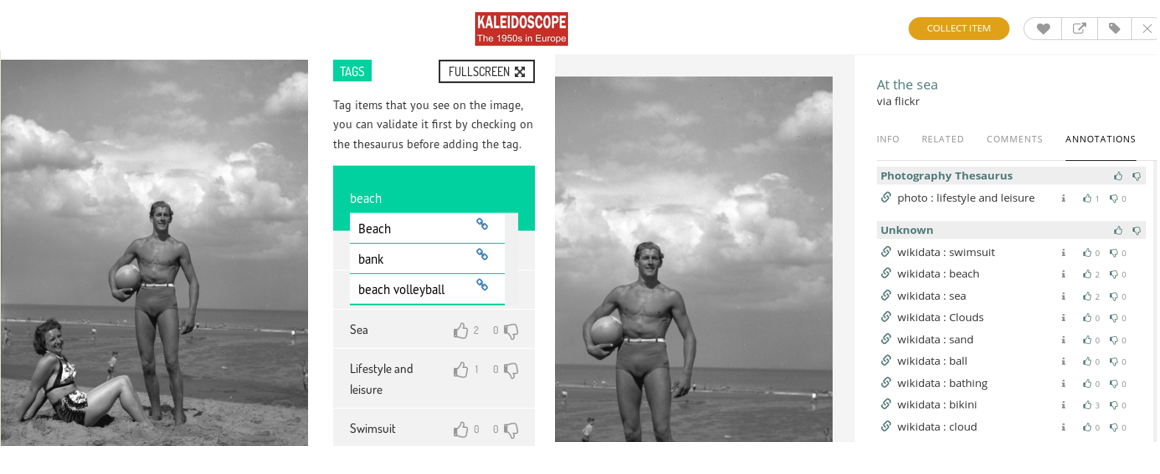
The annotation process (left) and the annotations as displayed in the Kaleidoscope portal (right)